Reverse Engineering EF Core Model and Data Validation Techniques

While working with ASP.NET Core and Entity Framework Core you need to create
data model for your application. This calls for creating a DbContext class along
with one or more entity classes. Luckily, EF Core allows you to reverse engineer
the model from an existing database. To that end this article discusses how that
can be accomplished.
Model creation and data validation options
While creating EF Core model and using it in web applications you are looking
for two main aspects:
- How to map entity POCO structure with the database structure
- How to perform data validations in terms of user input and MVC's model
Beginners often get confused between the available options for performing
these tasks. Hence, it's worthwhile to briefly mention them here before we move
ahead to reverse engineering features of EF Core.
Two options for creating EF Core model
As far as creating EF model is concerned you have two options. You can
either create DbContext and entity classes manually OR you can use reverse
engineering to generate them automatically. This article doesn't discuss the
former approach. The latter approach will be discussed in the sections that
follow. Obviously, the reverse engineering approach can be used when you have
database schema ready with you.
Three options for mapping POCOs to database tables
When it comes to mapping POCOs to database tables you have two options: you
can follow certain conventions OR you
can use data annotations OR you can use Fluent API. The first approach requires
you to create your POCOs such that the class names are same as table names and
property names are same as table column names (there are a few more
conventions). The second approach
uses attribute based syntax to perform mapping with tables and columns. This is
a design time way to specify the mapping. The third option uses programmable
approach to model configuration and is a runtime way to specify the mapping.
Fluent API is often considered an advanced option because it provides certain
functionality that is not available with data annotations.
Two options for performing data validations
Here data validations means MVC level model validation (or view model
validation). Again there are two options to accomplish this task. You can either
use data annotations OR you can use
Fluent Validation
library. Fluent Validation is a popular .NET library for building strongly typed
validation rules.
If you look at the above options, it would be clear that Fluent API is
primarily used for mapping purposes. It doesn't provide data validation
capabilities (MVC level model validation). On the other hand data annotations
provide mapping as well as data validation capabilities. Although data
annotations provide both capabilities, some developers consider this mixing of
responsibilities as a poor development practice and prefer Fluent API over data
annotations.
Generate EF Core model from existing database using reverse engineering
Ok. Now let's generate EF Core model for tables in the Northwind database.
First of all create a new ASP.NET Core web application using MVC template. Then
open Visual Studio command prompt and go inside the web application's folder.
Then issue the following command:
dotnet ef dbcontext scaffold
"Server=.;Database=Northwind;Integrated Security=true;"
Microsoft.EntityFrameworkCore.SqlServer
-c AppDbContext
-o Data
-t Customers
-t Employees
Here we use EF core scaffolding command to generate DbContext class and
entity classes. The command takes a database connection string and data provider
name. In this case the connection string points to the Northwind database and
uses SqlServer data provider.
The -c option is used to specify the DbContext class name. In this case the
DbContext class will be named AppDbContext. The -o option is used to specify the
output folder where all the class files will be placed. In this example we store
the output in Data folder under project root. If the folder doesn't exist it
will be created for you. The -t option is used to specify a table name whose
entity class is to be reverse engineered. In this example we ask the tool to
reverse engineer Customers and Employees table. If you don't specify -t switch
then all the tables are used while scaffolding.
If you issue this command you will get output as shown in the following
figure.

Open the AppDbContext class and you will find that the model has been
configured using Fluent API.

By default the reverse engineering approach uses Fluent API to map the entity
classes with the database tables. If you would like to use data annotations
instead of Fluent API you can modify the command as follows:
dotnet ef dbcontext scaffold
"Server=.;Database=Northwind;Integrated Security=true;"
Microsoft.EntityFrameworkCore.SqlServer
-c AppDbContext
-o Data
-t Customers
-t Employees
--data-annotations
The --data-annotations switch indicates that data annotations are to be used
instead of Fluent API. This time you will find that Customers contains several
data annotations shown below:

Testing the behavior - Fluent API vs. Data Annotations
From our earlier discussion you know that Fluent API mainly provide mapping
capabilities whereas data annotations provide mapping as well as data validation
capabilities. You can quickly confirm this by creating a view like this:

The view simply displays Customer properties for editing using the
EditorForModel() helper. The ValidationSummary() helper displays validation
error messages if any.
The Index() actions responsible for supplying data to this view are shown
below:
public IActionResult Index()
{
using (AppDbContext db = new AppDbContext())
{
Customer obj = db.Customers.Find("ALFKI");
return View(obj);
}
}
[HttpPost]
public IActionResult Index(Customer obj)
{
using (AppDbContext db = new AppDbContext())
{
if (ModelState.IsValid)
{
db.Update(obj);
db.SaveChanges();
ViewBag.Message = "Model contains valid data!";
}
else
{
ViewBag.Message = "Model contains invalid data!";
}
return View(obj);
}
}
I won't go into the details of these actions since they are quite
straightforward.
Now, reverse engineer model using Fluent API and run the application. You
will find that ModelState.IsValid returns true even if you enter invalid data
(say you enter CustomerID greater than 5 characters). An exception is thrown at
SaveChanges() line when an attempt is made to save the data (the error might
vary depending on the kind of operation you are performing).
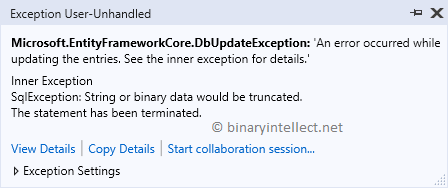
Now, reverse engineer model using data annotations and run the application.
This time validation works as expected and ModelState.IsValid returns false for
invalid data.

Using Fluent Validation with Fluent API
By now it should be clear to you that reverse engineering with Fluent API
needs some data validation strategy. Since you are using Fluent API for mapping
why not use Fluent Validation for data validations? That's what we are going to
do.
To use Fluent Validation you need to install the Fluent Validation library
using Manage NuGet Packages dialog.

Make sure to install FluentValidation.AspNetCore package as shown above.
Then add a new class called CustomerValidator in the Data folder (or whatever
folder you store your reverse engineered files). The CustomerValidator class
implements the validation rules and is shown below:
public class CustomerValidator :
AbstractValidator<Customer>
{
public CustomerValidator()
{
RuleFor(x => x.CustomerId).NotNull().Length(5);
RuleFor(x => x.CompanyName).
NotEmpty().Length(3, 50);
RuleFor(x => x.ContactName).
NotEmpty().MaximumLength(50);
RuleFor(x => x.Country).MaximumLength(50);
}
}
Notice that the CustomerValidator inherits from AbstractValidator<Customer>
base class. We configured the validation rules such as CustomerId property
doesn't contain a null value and its value is exactly 5 characters. The
CompanyName property is not empty and and 5 to 50 characters. The ContactName is
configured to be not empty and maximum length of 50 characters. Finally, Country
is configured to have maximum of 50 characters. You may read the
official documentation of Fluent Validation to know more about configuring
validation rules.
Now open the Startup class and add the following lines in the
ConfigureServices()
services.AddMvc().AddFluentValidation();
services.AddTransient<IValidator<Customer>,
CustomerValidator>();
The above code registers FluentValidation with the DI framework. Then it
registers a transient instance of CustomerValidator with the DI container. This
way our web application is now aware of Fluent Validation.
Run the application and try entering some invalid data. This time
ModelState.IsValid will return false because Fluent Validation library is doing
the validations for us.
That's it for now! Keep coding!!